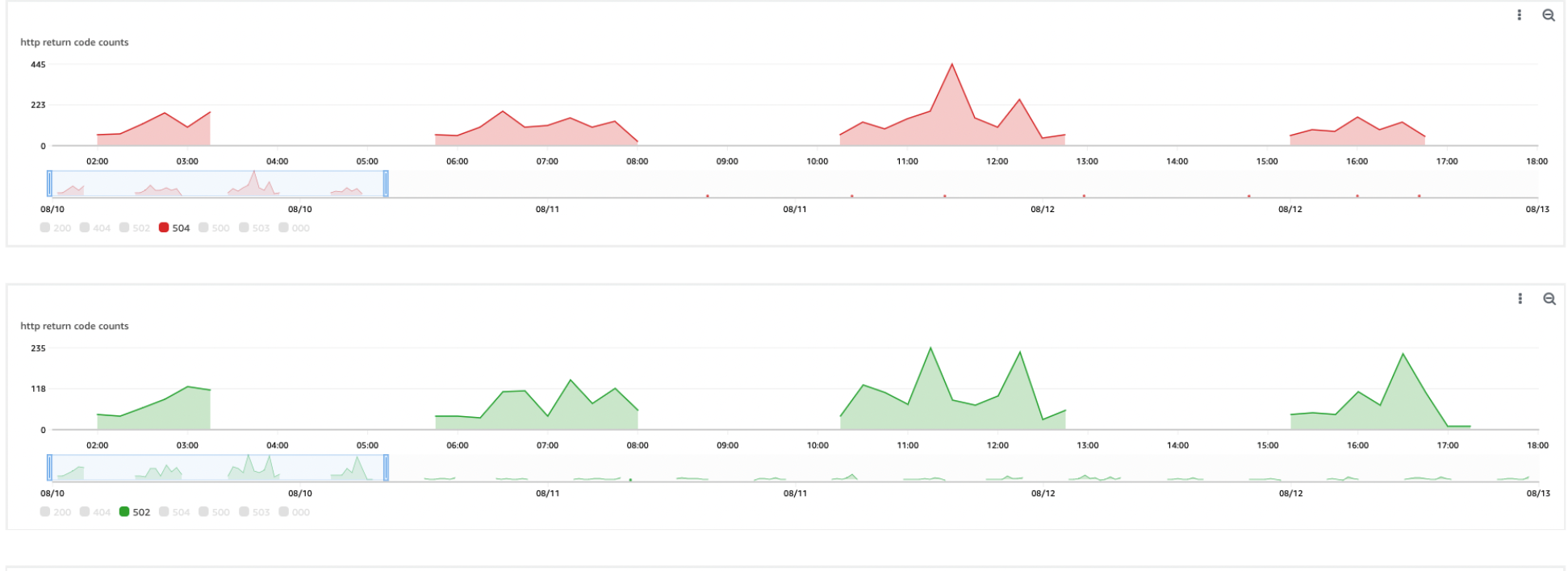
Last year, I had the opportunity to assist a client (also a friend) in setting up monitoring for their services running on Kubernetes. While setting up the dashboards, I noticed the correlation as the number of nodes and pods decreases (the horizontal pod autoscaling and cluster autoscaler kicked in), there were also spikes in number of 5xx errors, like 502 (Bad Gateway) and 504 (Gateway Timeout). I mean those spikes happened whenever pods were terminated during scaling events or deployments. The client had several Python FastAPI microservices running on EKS cluster with 10-20 t3.xlarge nodes.
The client had the Kubernetes cluster setup with ingress and ALB. The target-type annotation was set to ip, which means that the ALB sends traffic directly to the pod IPs, bypassing the Service’s node port abstraction. The ALB maintains its own list of targets (the pod IPs)
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/healthcheck-path: /health
...This one is important, as it affects how we chose to solve the issue later. If you want to know more about the pros and cons of this target-type annotation, I suggest quick read this link.
Understanding the pod termination process
When Kubernetes needs to terminate a pod, it follows a specific sequence:
- Initiation: When a pod termination is requested (e.g., via
kubectl delete pod, or during scale down), the Kubernetes API server updates the pod’s metadata, marking it for deletion. The pod’s status is set to “Terminating“.
At this point, new traffic is no longer routed to it, as the pod endpoint is marked as “ready: false” in the service’s EndpointSlices.
kubectl get endpointslice -o yaml fastapi-service
...
addresses:
- 10.12.1.201
conditions:
ready: false
serving: true
terminating: true
... Grace Period: defined by the terminationGracePeriodSeconds in the
pod’s spec default is 30 seconds. The terminationGracePeriodSeconds
starts counting at t=0, immediately when the pod is marked
“Terminating“.
2. PreStop Hook (if configured): Before sending any signals, Kubernetes executes the PreStop hook if it’s defined in the pod’s configuration.
3. SIGTERM Signal: After the PreStop hook completes (or immediately if no hook is defined), Kubernetes sends a SIGTERM signal to the process with PID 1 in the container. The application process should catch this signal and terminate gracefully.
4. SIGKILL Signal: If the process hasn’t terminated by the end of the grace period, Kubernetes sends a SIGKILL signal, which forcefully terminates the process immediately.
The Challenge: 5xx Errors During Pod Terminations
There are Python FastAPI pods, running with async uvicorn, and they ran smoothly—until pods needed to terminate. Whether due to autoscaling events, and sometimes a deployment rollout, there are notieable number of requests failing with 5xx errors. Some customers did notice the error and reported.
Digging into the logs and metrics, we pinpointed the issue: pods were being terminated abruptly while still processing requests.
In Kubernetes, when a pod is slated for termination:
– The kubelet sends a SIGTERM signal to the main process (PID 1) inside the container. This signal is designed for the application to shut down gracefully—finish ongoing tasks, close connections, then exit nicely.
– If the application doesn’t handle SIGTERM properly, Kubernetes waits for a grace period (defaulting to 30 seconds) before sending SIGKILL, which force stops the process. This hard stop could result in the pod’s 502 and 504 errors, as the in-flight requests were cut off during execution.
Step 1: Fixing Signal Handling by modifying the Dockerfile
The root cause lay in how the application was launched inside the container. Many Dockerfiles, including the client’s original one, use the shell form of the CMD instruction—something like:
CMD uvicorn app:app --host 0.0.0.0--port 80 --workers 4
In this form, the command runs inside a shell, dash in this case, which becomes PID 1—the init process, and the python processes become the child processes.

SigCgt (signals caught) refers to the signals that a process has registered a custom handler for. Here we can translate
SigCgt: 0000000000010002 to SIGHUP (1) and SIGCHLD (17). There is no SIGTERM (15) here so the shell isn’t catching it.
If a process custom handler doesn’t handling the SIGTERM, the default action by the default handler SIG_DFL is taken. The default behavior for certain signals like SIGTERM, when applied to PID 1, is to ignore them. This is a safety mechanism and also the critical point here.
To resolve this, we updated the Dockerfile to use the exec form of CMD:
FROM python:3.12-slim
WORKDIR /app
COPY . /app
COPY requirements.txt .
RUN pip install -r requirements.txt
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "80", "--workers", "4"]Now when using exec form, This runs the command directly without a shell, making the uvicorn process runs directly as PID 1 and can handle SIGTERM natively.
With this change, uvicorn receives the SIGTERM signal directly when Kubernetes initiates pod termination. Uvicorn support supports graceful shutdown by default when signaled, allowing the app to finish processing active requests and close connections cleanly before exiting.
Step 2: Controlling in-flight requests with a PreStop Hook
Fixing signal handling was a critical step, but it wasn’t enough on its own. Even with the application shutting down gracefully, new requests could still hit the pod during the termination window, and fails if the pod was killed before those requests completed. To address this, I added a PreStop hook to the Kubernetes deployment.
The PreStop hook serves two key purposes:
- Fail the Health Check: It modifies the application’s health check to return an unhealthy status, prompting Kubernetes and the load balancer to stop sending new traffic.
- Delay Termination: It pauses execution long enough for existing requests to complete and for traffic to drain.
The client’s health check was implemented in /app/health.py. We crafted a PreStop hook to alter this file and introduce a sleep period:
preStop:
exec:
command: ["/bin/sh", "-c", "sed -i 's/health/nothealthy/g' /app/health.py && sleep 50"]Here’s how it works:
- The sed command edits /app/health.py, replacing “health” in the file with “nothealthy” to make the health endpoint return an error (e.g., a 500 or 503 status code).
- The sleep 50 command pauses for 50 seconds, giving the load balancer time to detect the unhealthy status and reroute traffic, while allowing in-flight requests to finish.
This approach ensures a clean handoff: the pod signals it’s no longer fit to serve traffic, and the sleep duration provides a buffer for graceful shutdown.
Where is that 50 seconds from? How can we determine the sleep time for the PreStop hook command?
To determine an appropriate sleep time for the PreStop hook, we needed to consider the application’s behavior and the load balancer’s configuration. The maximum response time for their FastAPI application was around 10 seconds—meaning no request should take longer than that to complete under normal conditions.
(Note: This isn’t the same as a keep-alive timeout, which targets idle connections; here, we focus on active request processing time)
Here’s how we reasoned through the sleep duration:
- Load Balancer Deregistration: Most load balancers, like an AWS Application Load Balancer (ALB), use health checks to determine pod availability. A typical setup with a 10-second health check interval and an unhealthy threshold of 3 failed checks, plus 5 seconds for the last healthcheck timeout, it takes about 35 seconds for the load balancer to stop sending traffic after the health check begins failing.
- Request Completion: With a maximum response time of 10 seconds, any request that starts just before the health check fails needs up to 10 seconds to finish.
- Safety Buffer: Adding some for variability, such as network latency or slightly slower responses under load.
Calculating this:
- Load balancer deregistration (35s) + maximum response time (10s) = 45s.
- Adding a 5-second buffer for safety = 50s.
Thus, we came up with a sleep duration of 50s in the PreStop hook.
- The load balancer stops routing new traffic within ~35s.
- Existing requests have up to 10s to complete.
- The extra 5s cover any edge cases.
As the terminationGracePeriodSeconds starts counting from the beginning t=0 and default is 30 seconds, we also need to adjust the value. At least it should be equals to sleep value (50s) adding a few seconds for SIGTERM handling.
...
spec:
terminationGracePeriodSeconds: 60 # Pod level
containers:
- name: app
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sed -i 's/health/nothealthy/g' /app/health.py && sleep 50"]
...For the client’s FastAPI app, 50-second sleep and 60-second terminationGracePeriodSeconds proved effective. These values can be tuned based on your application’s specific response times and settings.
Before and After Result
Before these changes, the client saw a measurable spike in 5xx errors during pod terminations. In a typical deployment or scaling event, they might log 50-100 failed requests—roughly 5-10% of traffic during those windows, depending on load. These errors, while not huge, were enough to annoy users and complicate monitoring.
After implementing the updated Dockerfile and PreStop hook, the results were striking:
- Before: 50-100 5xx errors per deployment, with 502s from dropped connections and 504s from timeouts.
- After: 0-5 5xx errors per deployment—a reduction of over 90%.
This dramatic drop came from two factors: the application now complete in-flight requests, shut down gracefully, and the PreStop hook prevented new traffic from hitting terminating pods. The remaining handful of errors were likely edge cases (e.g., requests starting at the exact moment of shutdown), but the impact was negligible.
Notes
By default, the value of annotation alb.ingress.kubernetes.io/target-type is instance.
- Traffic Path: traffic is routed through the node ports of a Kubernetes Service, instead of directly to pod IPs.
- Role of the Service: The Service acts as an intermediary, deciding which pods receive traffic based on their readiness, which is determined by readiness probes, and also the ready status of the pod IP in the EndpointSlices.
- ALB Health Checks: The ALB performs health checks against the node IPs and node ports (e.g., http://node-ip:node-port/health), not directly to pod IPs.
If you are using the ALB annotation target-type: instance, and getting the 5xx error during pod termination, you primarily need to focus on tuning the terminationGracePeriodSeconds (should be max response time + a few seconds as buffer)
Key Takeaways
If you’re running services in Kubernetes, using “target-type: ip” for ALB and noticing 5xx errors during pod terminations, here’s how to tackle them:
- Use Exec Form in Docker: Ensure your application runs as PID 1 using CMD [“command”, “arg1”, “arg2”] in your Dockerfile. This allows it to handle SIGTERM signals directly for a graceful shutdown.
- Add a PreStop Hook: Modify your health check to fail and include a sleep duration, giving the load balancer and application time to drain traffic and complete requests.
- Tune the Sleep Duration: Base it on your app’s maximum response time (e.g., 10 seconds for the backend) and load balancer health check settings (e.g., 35 seconds to deregister), plus a safety margin. For many apps, 50 seconds is a solid starting point.
Graceful pod termination isn’t just a nice-to-have in Kubernetes now. These steps can do the same for you. You can test these changes in your environment, monitor your error rates, and adjust as needed.
References:
- Pod Termination: https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/#pod-termination
- EndpointSlices: https://kubernetes.io/docs/concepts/services-networking/endpoint-slices
- terminationGracePeriodSeconds: https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/#probe-level-terminationgraceperiodseconds
- PreStop Hook: https://kubernetes.io/docs/concepts/containers/container-lifecycle-hooks/#container-hooks
- AWS ALB Annotation: https://kubernetes-sigs.github.io/aws-load-balancer-controller/v2.1/guide/ingress/annotations
- ALB Ingress: https://docs.aws.amazon.com/eks/latest/userguide/alb-ingress.html
Leave a Reply